
...making Linux just a little more fun!
The Front Page
By Heather Stern

![[BIO]](misc/cover/xensource.gif)
XenSource is the company that
commercially supports the Xen hypervisor environment and
support tools for using it. The software uses paravirtualization for
high performance, running several guest domains on one parent OS.
I would describe Zen, but if it can be described successfully, would it
really need a description anymore?
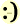 The gate to an open
mind and heart is inside.
The gate to an open
mind and heart is inside.
This really is the inside gate of my garden. Guests in my domain are
welcome to coffee anytime!
Heather is Linux Gazette's Technical Editor and The Answer Gang's Editor
Gal.
![[BIO]](../gx/2002/note.png) Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather is a hardware agnostic, but has spent more hours as a tech in
Windows related tech support than most people have spent with their computers.
(Got the pin, got the Jacket, got about a zillion T-shirts.) When she
discovered Linux in 1993, it wasn't long before the home systems ran Linux
regardless of what was in use at work.
By 1995 she was training others in using Linux - and in charge of all the
"strange systems" at a (then) 90 million dollar company. Moving onwards, it's
safe to say, Linux has been an excellent companion and breadwinner... She
took over the HTML editing for "The Answer Guy" in issue 28, and has been
slowly improving the preprocessing scripts she uses ever since.
Here's an autobiographical filksong she wrote called
The Programmer's Daughter.
Copyright © 2005, Heather Stern. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
Firewall logging to MySQL - the quick and easy way
By Anonymous
Security is a journey, not a destination. One good step along
the way is to review and analyze your firewall logs and syslog
messages on a regular basis. Unfortunately, the plain text logs
produced by syslog are not in a form that is easily
analyzed. Also, unless you are using syslog-ng, your
firewall logs are probably scattered all over the various system
message log files.
This article will show you how to move your firewall logs from
syslog text files to a MySQL database in 10 minutes or
so. The following examples were carried out on a SuSE 10.0 system
but you can easily adapt them for other distributions.
1. Verify kernel settings
You can skip this step if you are using the default SuSE 10.0
kernel. The stock kernels that come with most distributions should
be fine, but you will need to make sure you have your kernel
compiled with the CONFIG_NETFILTER,
CONFIG_IP_NF_IPTABLES,
CONFIG_IP_NF_FILTER, and
CONFIG_IP_NF_TARGET_ULOG options. Most firewalls will
also need CONFIG_IP_NF_CONNTRACK,
CONFIG_IP_NF_FTP, and
CONFIG_IP_NF_IRC.
If you have a file called
/proc/config.gz, it means
your kernel was compiled with the IKCONFIG option.
/proc/config.gz is the compressed version of the
.config file that was used to generate that kernel, so
you can check if you have the necessary options for
netfilter and
ulog with this command:
gunzip -c /proc/config.gz | grep -E 'CONFIG_(NETFILTER|(IP_NF_(IPTABLE|FILTER|TARGET_ULOG)))'
If they are not set as modules or compiled into the kernel you
will need to change them and recompile the kernel. In
menuconfig the following options need to be set:
Networking options > Network packet filtering
Networking options > Netfilter Configuration > IP tables support
Networking options > Netfilter Configuration > Packet filtering
Networking options > Netfilter Configuration > ULOG target support
You might also want to verify that iptables is
compiled with ulog support.
2.1. Install MySQL
You can go directly to 2.2. if you have MySQL already setup.
Otherwise:
apt install mysql
/etc/init.d/mysql restart
chkconfig mysql on
If you are using SuSE and do not have apt4rpm installed on your
system, I highly recommend that you do so, as it will greatly
simplify your package management issues.
You also need to set a password for the MySQL root user:
mysqladmin -u root password 'yourpassword'
2.2. Initialize the database
Type in:
mysql -p -u root
then enter your password at the prompt. Once you have logged into
your MySQL database, enter the following commands to prepare the
database to receive firewall logs from ulog.
create database ulogdb;
use ulogdb;
source /path/to/nulog/scripts/ulogd.mysqldump;
grant select,insert,update,drop,delete,create temporary tables, on ulogdb.* to ulog@localhost identified by 'ulogpass';
flush privileges;
quit;
So what happened here?
- We created a database ulogdb to host our logs
- We executed the SQL script
ulogd.mysqldump,
preparing the database for nulog-php, it allows to store more
information than the MySQL table provided with ulogd, and you can
find it in the scripts directory of nulog-php or right here.
- We created an user “ulog” (with pass
“ulogpass”) to have read/write access to that database.
I highly recommend that you enter a different password than this
example uses.
3.1. Install ulogd
You will need to install the logging daemon
ulogd:
apt install ulogd-mysql
3.2. Configure ulogd.conf
Edit /etc/ulogd.conf to match what we set up previously:
[MYSQL]
table="ulog"
pass="ulogpass"
user="ulog"
db="ulogdb"
host="localhost"
You should change the password “ulogpass” to the
password you set in the GRANT command in your MySQL database. Now
uncomment the following line to send the data to MySQL:
plugin /usr/lib/ulogd/ulogd_MYSQL.so
and comment out the following two lines to prevent logging to a
text file:
#syslogfile /var/log/ulogd.syslogmenu
#plugin /usr/lib/ulogd/ulogd_LOGEMU.so
Now restart the ulogd daemon and set it to be automatically
started at boot time with chkconfig:
/etc/init.d/ulogd restart
chkconfig ulogd on
4. Redirect iptables Logging
The following sed command switches all your
iptables rules to log through ULOG, we will assume that you store
your iptables ruleset in a file called “iptables”
(usually in /etc/sysconfig/ or /var/lib/)
sed 's/LOG/ULOG/'; /etc/sysconfig/iptables > /etc/sysconfig/uiptables
iptables-restore < /etc/sysconfig/uiptables
You are now all set up! All the logs from your firewall are now
being logged in your MySQL database. Don't forget to update your
firewall startup script so the new iptables are taken into
account.
5. Import Your Old Logs
So far, so good, but you probably would like to have your old
logs in MySQL also. Here is a little perl script to allow you to
import your old text logs to MySQL. Some of the regexps are reused
from adcfw-log. You
can usually find your netfilter logs in /var/log/firewall-XXXXXX.gz
or /var/log/messages-XXXXXX.gz. To import:
gunzip -c /var/log/firewall-XXXXXX.gz | nf2sql.pl
Repeat for each of your other log files. To process a current log
file (or other uncompressed log file) such as /var/log/messages or
/var/log/firewall:
nf2sql.pl < /var/log/messages
That's it!
6. Analyze the Results
To analyze your logs in MySQL you can use nulog or webfwlog
Links
This article was partly inspired by
this article (only available in Spanish).
The original ulog page can be found here.
If you want to push it further and log all system messages to
MySQL, you can take a look at this HOWTO setup PHP
syslog-ng wiki entry.
Here is a reason to move away from the usual text file
logging.
If you do not have your iptables set already, you can easily
build a good ruleset with shorewall, firehol or firestarter.
A. N. Onymous has been writing for LG since the early days - generally by
sneaking in at night and leaving a variety of articles on the Editor's
desk. A man (woman?) of mystery, claiming no credit and hiding in
darkness... probably something to do with large amounts of treasure in an
ancient Mayan temple and a beautiful dark-eyed woman with a snake tattoo
winding down from her left hip. Or maybe he just treasures his privacy. In
any case, we're grateful for his contribution.
-- Editor, Linux Gazette
Copyright © 2005, Anonymous. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
Using the GNU Compiler Collection (Part2)
By Vinayak Hegde
In the last
article we saw some of the basic GCC options, and noted that it
supports several CPU architectures. One of the topics we will cover
in this article is how to turn on optimizations for different
architectures and what happens when they are turned on. We will
also look at some other nifty tricks which we can do with GCC.
Adding symbols for profiling and debugging
Profiling is a method of identifying sections of code that
consume large portions of execution time. Profiling basically works
by inserting monitoring code at specific points in the program.
This code can be inserted by using the -pg option of
GCC.
When debugging we need extra information added to the binaries.
Programs compiled with the -g flag additional information
which can be used by gdb (or other debuggers) is added to the
binary. This increases the size of the binaries but is necessary
for debugging. When compiling debugging binaries we should turn off
all optimization flags. GCC can add debugging information in
several different formats such as stabs, dwarf-2 or coff
format.
$ gcc -g -o helloworld helloworld.c #for adding debugging information
$ gcc -pg -o helloworld helloworld.c #for profiling
Programs compiled with profiling and/or debugging turned on are
usually referred to as debug binaries, as opposed to
production binaries which are compiled with optimization
flags.
Monitoring compilation times
We previously saw that the compilation of the program to get an
executable binary consists of different phases.
Each of the main compile stages
(compiling to assembly language, assembling and linking) is done by
different executables (e.g. cc1, as and collect2). We use the
-time option to GCC to get a breakdown of the time
required for each stage.
$ gcc -time helloworld.c
# cc1 0.02 0.00
# as 0.00 0.00
# collect2 0.04 0.01
We can also gather more fine-grained statistics about the
various stages of the compiler cc1 using the -Q option.
This shows the real time spent as well as time spent in userspace
and kernel modes.
$ gcc -Q helloworld.c
main
Execution times (seconds)
preprocessing : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.24 (38%) wall
parser : 0.01 (50%) usr 0.00 ( 0%) sys 0.02 ( 3%) wall
expand : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.03 ( 5%) wall
global alloc : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.03 ( 5%) wall
shorten branches : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.04 ( 6%) wall
symout : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.01 ( 2%) wall
rest of compilation : 0.01 (50%) usr 0.00 ( 0%) sys 0.00 ( 0%) wall
TOTAL : 0.02 0.00 0.64
GCC Optimizations
Before we move on to optimizations, we need to look at how a
compiler is able to generate code for different platforms and
different languages. The process of compilation has three
components:
- The Front End: This is responsible for interpreting the
text and converting into an efficient form for manipulation by the
computer. This efficient form is generally a specialized form of
the tree data structure. There are hardly any optimizations done at
this stage. This stage will be different for each language
supported by GCC.
- The Middle End: In this phase, the tree data structure
is manipulated and pruned to improve the structure for the code
generation phase. The optimizations that are performed in this
phase are common to all languages and platforms. These include
constant folding, strength reduction, algebraic simplification and
common sub-expression elimination. Discussion of these
optimizations is beyond the scope of this article, but you can
refer to the "Compilers" book by Aho, Sethi and Ullman (ISBN
0201100886, also called the "Dragon Book") for more detailed
information.
- The Back End: This is the final phase before emitting
binary code for a particular platform. This is the phase in which
platform specific optimizations are done. The compiler can use
platform-specific information such as extended/specialized
instruction sets such as MMX/SSE2/3DNow!. Different CPUs have
different number of registers/internal caches/pipeline structures.
Optimizations can also be directed towards these architectural
differences to exploit them and maximize the speed of the binary
code emitted by the final code generation phase. The types of
optimization which can be done in this phase can mainly divided
into two categories - Register Allocation and Code Scheduling.
There are two kinds of optimizations possible - optimizations
for speed and optimizations for space. In an ideal world, both
would be possible at the same time, (Actually some optimizations do
both - such as common sub-expression elimination). More often than
not optimizing for speed increases the memory footprint (the size
of the program loaded in memory) and vice versa. Expanding
functions inline is a good example of this case. Inlining functions
reduces the overhead of a function call but ends up replicating
code wherever the inline function has been called, thus increasing
the size of the executable. Turning on optimizations will increase
the compilation time as the compiler has to analyze the code
more.
GCC offers four optimization levels. These are specified by the
-O<Optimization Level> flag. The default is no optimization
or -O0 (notice the capital O). Various optimizations are turned on
by the each of the different levels (-O1, -O2 and -O3). Even if we
give higher optimization levels such as -O25, they have the net
effect of enabling the highest level of optimizations (-O3). In
addition to these four optimization level there is another
optimization level -Os which enables all the optimizations for
space as well as those optimizations which do not increase the size
of the code but give speed improvements. In -O1 optimization level,
only those optimizations are done which reduce code size and
execution time without increasing compilation times significantly.
In -O2 optimization level, those optimizations which do have a
space-execution time tradeoff are done. Almost all optimizations
are turned on by -O3 optimization level but compilation time might
increase significantly by turning it on.
$ gcc -O3 -o hello3 helloworld.c
$ gcc -O0 -o hello0 helloworld.c
$ ls -l
-rwxr-xr-x 1 vinayak users 8722 2005-03-24 17:59 hello3
-rwxr-xr-x 1 vinayak users 8738 2005-03-24 17:59 hello0
$ time ./hello3 > /dev/null
real 0m0.002s
user 0m0.001s
sys 0m0.000s
$ time ./hello0 > /dev/null
real 0m0.002s
user 0m0.000s
sys 0m0.003s
As seen above, compiling the program with -O3 optimization level
reduces the size of the executable compared to the compiling with
-O0 optimization level (no optimization)
It is also possible to have CPU or architecture specific
optimizations. For example a particular architecture may have
numerous registers. These can be utilized by the register
allocation algorithm intelligently so as to store temporary
variable between calculation to minimize cache and memory accesses
thus ensuring considerable speed ups in CPU-intensive operations.
Some of the platform specific optimization flags can be done using
-march=<architecture type> or -mcpu=<CPU name>. For the
x86 and x86-64 family of processors, -march implicitly implies
-mcpu. Some of the architecture types options in this family are
ix86 (i386, i486, i586, i686), Pentiumx (pentium, pentium-mmx,
pentiumpro, pentium2, pentium3 ,pentium4) and athlon (athlon,
athlon-tbird, athlon-xp, opteron). But executables built with
platform specific flags may not run on other CPUs. For example,
executables generated with the -march=i386 will run on i686
platform because of backward compliance of the platforms. However,
executables generated with the -march=i686 may not run on the older
platforms as some of the instructions (or extended instruction
sets) do not exist on older CPUs. If you use the Gentoo Linux
distribution, you might be already familiar with some of these
flags.
$ gcc -o matrixMult -O3 -march=pentium4 MatrixMultiplication.c #optimise for Pentium 4
$ gcc -o matrixMult -O3 -march=athlon-xp MatrixMultiplication.c #optimise for Athlon-XP
Also you can give specific flags for optimizations at the
command line such as -finline-functions (for integrating simple
functions into their callers) and -floop-optimize (to optimize loop
control structures). The important thing to remember is that the
order of the flags on the command line matters. The option on the
right will override ones on the left. This is a good way to choose
particular options without cluttering the compilation command line.
It is also possible to do it for platform-specific
optimizations.
$ gcc -o inlineDemo -O3 -fno-inline-functions InlineDemo.c
$ gcc -o matrixMult -march=pentium4 -nosse2 MatrixMultiplication.c
In the example, the optimization level -O3 will enable inlining
of functions - the effect is same as -O2 -finline-functions
-frename-registers. So if you have the option -fno-inline-functions
on the right on the command line, it will disable inlining of
functions. This command will turn on all the Pentium4 specific
optimizations but code generated will not contain any MMX, SSE and
SSE2 instructions.
Supported options
All the options supported by GCC on your machine can be seen by
giving the following command:
$ gcc -v --help | less
This will list out all the different options that are supported
by GCC and the processes invoked by GCC on your machine. This is a
pretty huge list and should contains most of the options discussed
by us in this article and the earlier one in this series and
more.
Conclusion
In this article, we looked mainly at the various GCC
optimizations options and how they work. In the next part of this
series we will look at another development tool called make used
for building big projects.
Resources
Vinayak Hegde is currently working for Akamai Technologies Inc. He
first stumbled upon Linux in 1997 and has never looked back since. He
is interested in large-scale computer networks, distributed computing
systems and programming languages. In his non-existent free time he
likes trekking, listening to music and reading books. He also
maintains an intermittently updated blog.
Copyright © 2005, Vinayak Hegde. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
A New Scanner with XSANE and Kooka
By Edgar Howell
Introduction
Long before my old copier (a multifunction unit) died, I was
looking for a long-term, non-combo solution. For quite a while I
have wanted a flatbed scanner to enable copying not only something
from the revenuers for our accountant but also the occasional page
from a book or magazine without having to destroy the publication
first, so I really wanted a single-function device.
I also did not want another something requiring ink or toner or
whatever. Besides, a satisfactory network printer was available.
All that was really needed was a source of input, i.e. a
scanner.
After much researching of product reviews and a bit of ping-pong
with http://SANE-project.org, I
settled on something with which I am quite happy.
The Scanner
For what it is worth, my choice was a Canon LiDe 20 which cost €55
(about US$70 last summer) from Amazon - no shipping charges,
delivery in about 10 days. The LiDe 30 is supposed to produce
slightly better quality than the LiDe 20, but not in proportion to
the difference in price.
This is not heavy-duty hardware, and it is not intended to be
out for lots of use every day. Instead it has a foot that lets it
be stored upright out of the way on the floor next to the PC when
not in use. It connects to the PC through USB connection when in
use. It seems to be ideal at home or in a small office.
But the hardware isn't as important as the software and the
process of obtaining and using it. And thanks to the help of the
folks at SANE-project.org, selecting hardware was almost a trivial
exercise and using it equally easy. They have an incredible amount
of information on the performance of various scanners under
GNU/Linux. I did glance at the literature that came with the
hardware but none of the information or software provided by the
manufacturer was needed.
Software Choices
In place of the manufacturer's software, I installed XSANE (the
graphical front-end for SANE). Since SuSE had Kooka (the KDE
equivalent of XSANE), I installed that as well. Because much of my
research had been at the SANE project, I planned on using XSANE,
but then decided "why not Kooka?"
Usually GUI-based programs are flexible, have lots of choices
and can be tweaked on-the-fly as needed. They don't necessarily
work well with repetitive, run-of-the-mill situations, however.
What I really wanted was exactly that: a quick copy off to the
network printer. So, OK, it isn't yet apparent how these guys can
help, but let's check them out.
As it turns out, for me at least, Kooka has one advantage: it
can print without having to first save a file, then start some
other program to do the actual printing. That makes it simple to
use it with the scanner and network printer as an alternative to a
single-purpose copier.
Running the Programs
When started, both ask for confirmation of the device to use.
But Kooka starts a single window, subdivided into 3 sections for a
list of recent scans, settings, and preview/current scan, while
XSANE starts 4 separate windows (there are more available)
providing preview and the like. Since I am a keyboard aficionado
from the days of the typewriter and not a mouse-user at all, I
prefer Kooka's behavior - XSANE turns Alt-TAB (tabbing among
windows on the current desktop) into a bit of a farce.
Both allow selecting either color, black-and-white, or grayscale.
They also have buttons for the usual manipulations to rotate or
mirror and the like. And they each show you the results of scanning
as well as offering a preview scan, again Kooka within a section
inside the window, XSANE starting another window for this.
To me it seems pretty clear that printing was never really high
priority in either software package, at least not in the sense of
using a scanner as part of a replacement for a copier. Kooka has a
print button, and XSANE allows access to Gimp with which one can
print (at least in theory; this is something I haven't yet
pursued).
Kooka also turns about 2/3 of a printed page into almost 14MB
for the postscript printer. Patience... The
quality isn't bad, though. To be fair, the quality on the CRT is
far better than on the printer, not a photo-quality device.
Since I am very new to the scanning game, I don't yet appreciate
or even understand much of the available functionality, but there
is lots more!
Conclusion
When all is said and done, I am extremely impressed with what
SANE, the two GUI interfaces, and the hardware accomplish. Super
quality on a CRT, ideal for sending to someone as an attachment to
an e-mail -- although I do need to play around with formats to find
something less than 1MB for my analog modem.
Recently a scan of less than one printed page from a newspaper
produced a JPEG of less than 150K, quite acceptable for forwarding
as an attachment. This wasn't even on my original wish-list!
As far as the occasional "quick copy" is concerned there is a
trade-off. It requires some time to move the scanner to a free area
somewhere and attach it to a USB port. And then to start one of the
GUIs. But copying has never been a frequent requirement in this
SOHO and I have regained a bit of desk space.
This is clearly not the way to go for everybody, especially not
if you are short on space, such as in student housing or a small
apartment. It is ideal for a small office without continual need
for copying. In any case, do check out SANE before you look for
scanners or copiers.
Disclaimer
Use of scanners or copiers involves risk of violation of
copyright. To my knowledge in some jurisdictions there is the
concept of "fair use" which includes quotes of ill-defined length.
When I copy something it is either (1) for my own personal
temporary use because I don't want to risk loss of or damage to the
original or (2) to forward to a friend along with attribution,
which I consider not only "fair use" but advertisement for the
source. I am not a lawyer, so use your own judgment.
Edgar is a consultant in the Cologne/Bonn area in Germany.
His day job involves helping a customer with payroll, maintaining
ancient IBM Assembler programs, some occasional COBOL, and
otherwise using QMF, PL/1 and DB/2 under MVS.
(Note: mail that does not contain "linuxgazette" in the subject will be
rejected.)
Copyright © 2005, Edgar Howell. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
The Basics of DNS
By Rick Moen
This article is a result of a discussion on the Answer Gang list,
in which Rick had brought up some interesting and common problems with DNS
(Domain Name Service). Since DNS is 1) a critical part of the Internet
infrastructure, 2) one of the most important - and yet very easy - services
Linux users can provide for each other, and 3) seemingly poorly understood
and seen as Deep Wizardry by most Linux enthusiasts, I asked Rick to expand
on the issue. His response follows.
-- Ben
Quoting Benjamin A. Okopnik (ben@linuxgazette.net):
> Rick, is there a _simple_ way to do basic DNS service, or is it an "all
> or nothing" sort of deal?
As a matter of logical categories, I can spot four distinct categories
of "DNS service": three of the four are dead simple. The fourth isn't
too difficult if you can refer to example zonefiles as your model.
Let's run through them, in turn, from simplest to most complex.
1. Recursive-resolver nameserver
The idea here is that you want to run a local nameserver for its caching
abilities, but you're not serving up authoritative DNS information of
your own or for someone else. You just want local machines to have
somewhere _local_ to query for name lookups, rather than having all
queries go across the wire to your ISP or elsewhere -- in order that,
most of the time, the answer's already in your nameserver's cache
because some other local machine also made the same query in the recent
past.
How do you enable it, you ask? You just turn on your nameserver.
Conventional DNS daemons (BIND9, MaraDNS, Posadis, PowerDNS, Twisted
Names, Yaku-NS) default to that sort of service, so you just switch
them on, and they work.
It's that simple.
Oh, and on the client side, you'll want to configure your various
machine to consult that nameserver in the future, via "nameserver"
entries in their /etc/resolv.conf files (the configuration file for
a client machine's "resolver library", the DNS client that on typical
Linux machines is built into 'glibc'). For client machines that are on
DHCP, you can automate this configuration via a suitable entry in
dhcpd.conf.
2. Caching forwarder nameserver
This type of service is only subtly different: Basically, the
nameserver daemon is one that lacks the smarts to, by itself, recurse
through DNS namespace on queries. Instead, it forwards all queries it
receives to a full-service nameserver elsewhere, which does the job.
Your local (caching forwarder) nameserver merely caches recently
received answers in case they're needed again, and of course ages the
cache. On the plus side, avoiding the very difficult coding problems
posed by _not_ handling recursive-resolver functionality means the
daemons can be very small and secure. Examples include dproxy, Dnsmasq,
DNRD, ldapdns, and pdnsd. pdnsd is particularly popular for really
small networks and laptops, in particular because it stores its
information in a disk-based cache that is (therefore) non-volatile.
How do you enable it? You put the IPs of one or more "upstream"
full-service nameservers in its configuration file (to tell it where to
forward to). Then, you turn it on, and it does its thing without
further fuss.
Again, it's that simple.
3. Secondary authoritative nameserver
This is the case where your friend Alice Damned
<alice@mydamnedserver.com>
asks you "Will you help me by doing secondary nameservice for
mydamneddomain.com?" You respond with, "Yes. My nameserver,
ns1.example.com, is at IP address 10.0.42.1. Please add that to your
allowed-transfer list, add an appropriate NS line to your zonefile, and
make my IP authoritative -- and we'll be in business." (Your telling
Alice that is kind of superfluous, actually, in the sense that those
things are her problem to figure out and implement, but let's suppose
you're trying to be helpful.) She also should have been equally
helpful by telling you what IP address her primary nameserver lives on.
If not, you do this, to find out:
$ dig -t soa mydamneddomain.com +short
The global DNS should return with a hosthame plus other
details (that you can disregard, for this purpose) from Alice's domain's
Start of Authority (SOA) record, something like:
ns1.mydamneddomain.com. alice.somewhere-else.com. 2005112200 7200 3600 2419200 86400
Which tells you that the primary DNS is claimed to be provided by
ns1.mydamneddomain.com. Use the 'host' command to get the
corresponding IP address. Let's say 'host' returns IP address 10.0.17.1
for that hostname.
How do you enable it? If you already are running a nameserver capable
of authoritative service (let's say, BIND9), then you need to lavish
five minutes of your time on a new "stanza" (paragraph) in your
nameserver's main configuration file, instructing it to (also) do
secondary nameservice for this domain. Again, using BIND9 as an
example, one would add this to '/etc/bind/named.conf' (or wherever you put
local additions, e.g., '/etc/bind/named.conf.local'):
//For Alice Damned <alice@somewhere-else.com> 212-123-4567 cellular
zone "mydamneddomain.com" {
type slave;
allow-query { any; };
file "/var/cache/bind/mydamneddomain.com.zone";
masters {
10.0.17.1;
};
};
Notice the comment line: You want to have on hand reliable means of
contacting Alice in case you need to talk to her about problems with
her domain -- and ideally means of communication that do not go
through the domain in question (as "Your domain is offline" mails
don't work too well when they're blocked by the fact that the domain's
offline).
In the case of BIND9, you can make your nameserver reload (or load) a
single zone such as mydamneddomain.com using BIND9's 'rndc'
(remote name daemon control) administrative utility, as the root user:
# rndc reload mydamneddomain.com
You should, if everything's configured right, now see your local cached
copy of Alice's primary server's zonefile (her domain's DNS information)
pop into (per the above) directory /var/cache/bind/, as file
mydamneddomain.com.zone. The moment you see that, you're done: The
contents and configuration of the zonefile are strictly Alice's problem.
If you don't see a copy of the zonefile appear (that copy operation
between nameservers being referred to as a "zone transfer"), then either
you've made some silly error, or Alice's nameserver isn't willing to
send yours the zonefile because she made some silly error. One of you
will probably find a clue in his or her '/var/log/{daemon.log|messages}'
file, fix the silly error, reload the zone or restart the nameserver as
required, apologise, and move on.
The nice thing about setting up secondary DNS is (1) it's pretty much
a set-up-and-forget affair on your end, and (2) it's the other person's
(Alice's) job to notice most sorts of problems. Moreover, it's usually
be her screw-up. So, doing secondary is an easy way to help a friend,
and involves only a tiny amount of one-time work.
4. Primary (master) authoritative nameservice.
This is the exception, the case where you actually need to know what
you're doing: This is where you're Alice. You have to maintain the
zonefile, which then gets propagated to all your secondaries via
zone-transfer mechanisms. You have to check on your secondaries from
time to time, making sure they haven't shot you in the foot by, e.g.,
forgetting to carry forward that "slave" stanza when they rebuild their
servers.
How do you enable it? Here is Alice's BIND9 "stanza" that operates her
end of the mydamneddomain.com operation:
//For myself
zone "mydamneddomain.com" {
type master;
allow-query { any; };
file "/etc/bind/mydamneddomain.com.zone";
allow-transfer {
//Joe Gazettereader <joe@example.com>, 212-765-4321 cellular
//ns1.example.com, is:
10.0.42.1;
};
};
Again, notice the comment lines, basically notes that Alice keeps for
her reference in case she wants to reach Joe in a hurry about him
shooting her domain in the foot. The "allow-transfer" list is the
list of IPs that are permitted to transfer (pull down) Alice's zonefile,
just as the "masters" list in Joe's earlier stanza listed the IPs of
machines that Joe's secondary service expects to be able to pull down
transfers from.
That leaves only the other difficult problem, which is the
composition and maintenance of Alice's zonefile. I'm going to wimp out and
claim it's out of scope for a brief article on simple DNS service, but will
point out that I publish a set of example BIND9 zonefiles and configuration
files that many people have used as examples to work from:
http://linuxmafia.com/pub/linux/network/bind9-examples-linuxmafia.tar.gz
Did I say "the other difficult problem"? Oops, there are more:
as publisher of primary (master) authoritative nameservice, you
need to be concerned not only that your domain's zonefile contents
are correct, but also that your domain itself is set up correctly, at
your domain registrar -- including enumerating, there, all of your
domain's nameservers to make them "authoritative" (i.e., tagged as a
reliable source of information on the domain's contents, as opposed to
just caching other nameservers' information if/when it happens to pass
through). Getting your domain records wrong can have a variety of ill
effects, and I can only recommend that (as with the finer points of
zonefile contents) you ask a knowledgeable person, maybe in your user
group, to check your work. Along those same lines, by all means use R.
Scott Perry's excellent DNS-checking CGI scripts at
http://www.dnsreport.com/, to check (in a single, amazingly useful
report) both your domain records and your (in-service) zonefiles.
It's important to note that there are many good nameserver daemons,
other than BIND9 -- which is important for historical reasons, but has the
annoying problems of being, as I say in my list of all known DNS server
programs for Linux, "a slow, RAM-grabbing, overfeatured, monolithic daemon
binary". That list is in my knowledgebase at "DNS Servers" on http://linuxmafia.com/kb/Network_Other/,
and contains a number of good choices for particular DNS situations. My
page aspires, among other things, to identify which type of the four
classes of service each package can do. I hope it's useful to people.
A wide variety of special-purpose primary-nameservice configurations are
possible, such as running a deliberately non-authoritative nameserver
(not shown in either your domain records or your zonefile) to provide
master DNS service from a protected machine inaccessible and
unadvertised to the public -- but details are beyond this brief
article's scope.
![[BIO]](../gx/2002/tagbio/moen.jpg) Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
His first computer was his dad's slide rule, followed by visitor access
to a card-walloping IBM mainframe at Stanford (1969). A glutton for
punishment, he then moved on (during high school, 1970s) to early HP
timeshared systems, People's Computer Company's PDP8s, and various
of those they'll-never-fly-Orville microcomputers at the storied
Homebrew Computer Club -- then more Big Blue computing horrors at
college alleviated by bits of primeval BSD during UC Berkeley summer
sessions, and so on. He's thus better qualified than most, to know just
how much better off we are now.
When not playing Silicon Valley dot-com roulette, he enjoys
long-distance bicycling, helping run science fiction conventions, and
concentrating on becoming an uncarved block.
Copyright © 2005, Rick Moen. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
DNS definitions
By Mike Orr (Sluggo)
DNS administrators often speak of master/slave servers,
primary/secondary servers, and
authoritative/non-authoritative servers. These do not all
mean the same thing but are often confused, both due to ignorance
and because the official usage has changed over time. So the person
you're speaking with may match any term with any of the meanings
below, and you'll have to figure out from context what he means.
This also means you should explain the term with anybody you're
speaking with, or at least put a few words of context so they know
which meaning you intend. Note that all these terms are
domain-specific. A server can be master for one domain while
simultaneously being slave for another domain.
master/slave
A
master server knows about a domain from its own
configuration files. A
slave server knows because
a master has told it. The slave is configured to retrieve that
particular domain from a certain master, either through a DNS zone
transfer or out-of-band (via 'rsync' or another mechanism.)
Master/slave is a private relationship between the servers; neither
the registrar nor the public know which IP is in the slave's
configuration file, or even that it is a slave. A slave's "master"
may in fact be slave to another master.
authoritative/non-authoritative
An
authoritative server is listed at the registrar
as having the official information for that domain. A
non-authoritative server has the information
because it earlier asked an authoritative server and cached the
answer. You might say, "All slave servers are non-authoritative,"
but this is misleading. Slave servers contact their masters
directly, while non-authoritative servers query the DNS hierarchy.
primary/secondary
These unfortunate terms were used for master/slave in earlier
versions of BIND. However, some people think the primary is the
first nameserver IP listed at the registrar, and any others others
are secondary. In fact, all the nameserver IPs are equal and
"authoritative"; the first one does not have a special status.
Still other people think primary means the nameserver listed in the
zonefile's SOA header, and others think primary means "the domain I
personally edit". So avoid the terms primary/secondary. If you do
use them (and it's hard not to let them slip out), take care to
explain what you mean.
When I originally set up a domain for a nonprofit organization,
I thought the first IP listed at the registrar had to be a master,
and the others had to be slaves or the zone transfers wouldn't work
properly. This turned out to be hogwash. A "hidden master" is
actually quite common. That's where the real records are kept at a
private or unadvertised server, and all the authoritative servers
are slaves. This protects you from attacks: the cracker can get the
money but he can't get the family silverware.
A question that comes up in those cases is "what value do I put
in the SOA record?" (the item at the top of a DNS zone that tells
which computers have the original configuration data). Traditional
practice is to list the masters, but that is what you would
not do if you really wanted to hide the masters.
No DNS program actually uses the SOA value for anything as far as
we know; it's more a note to humans than anything else, so you can
use it to cue yourself, or your fellow system administrators, in whatever way
you prefer.
 Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.
Mike is a Contributing Editor at Linux Gazette. He has been a
Linux enthusiast since 1991, a Debian user since 1995, and now Gentoo.
His favorite tool for programming is Python. Non-computer interests include
martial arts, wrestling, ska and oi! and ambient music, and the international
language Esperanto. He's been known to listen to Dvorak, Schubert,
Mendelssohn, and Khachaturian too.
Copyright © 2005, Mike Orr (Sluggo). Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
IT's Enough To Make You Go Crazy
By Pete Savage
I was warned by several people not to write this article whilst angry, for
fear of it turning into a scroll of unspeakable darkness, conjured by a
crazed homo sapiens wielding a typewriter. Dark materials such as these
tend not to get published in a fine monthly such as the Linux Gazette. I
decided from the outset that I would not to mention any names in this article. Not
only to protect the identity of the incompetent and the blazingly stupid, but
also to avoid the multitudes of replies standing up for company x, y or z.
I suppose in some ways you could ask the question, why are you writing this
article then? The answer? It just feels right, something I have to do.
For too long I've been idly wittering on to people I meet about my love of
open source software and the Linux OS, much to their disgust usually. Now
is the time to stand up and be counted. Below is a summary of a
particularly bad week, supporting common proprietary software.
And so the crazed homo-sapien began to type...
Earlier in the week I turned up at work and noticed a user's machine was
running particularly slow. At first I considered the user's choice of OS as
the limiting factor, but it was more than that. We're not talking "let's
make a cup of coffee and go gossip by the photocopier" slow, more the
kind of slow that causes a user to grow a beard - independent of their
gender. I sat down and clicked my little rodent friend, only to be greeted
by a barrage of web browser windows, offering me the latest in
pharmaceutical developments at a fraction of the retail price. My credit
card stayed firmly in its protective sheath and I resisted the temptation
to shave more weight off my already skinny frame. You can already guess
the issue that was at hand... SPYWARE and tonnes of it. The machine
seemed to be sporting its own division of MI5, MI6, and CTU, along with a
few KGB agents thrown in for good measure. I turned to the world wide web
to download a well known anti-spyware product, clicked the download button,
and wham, I was stopped quicker than a nitro equipped Ferrari F50.
The page you have requested is not accessible at this time.
The content group "Marijuana" has been filtered.
"For crying out loud," I screamed. I could tell this was going to be the
beginning of a very long week. Our Internet systems are externally
controlled and whilst I understand the reason for a good web filtering
system, I do not believe that the company involved had started trading in
illicit products. My heart sank.
I thought the next day would yield better luck. Perhaps I shouldn't have
been so hasty. I had set a backup going using the OS's supplied archiving
software at the end of last week. Having had little time on Monday to
go and check its completion, I found a few spare minutes early on Tuesday
whilst my brain was still actually firing neurons. I checked the
report... data transferred: 3,995,363,231 Bytes. Seemed reasonable enough,
not like I was going to sit down and count them. Elapsed time... 126 Days,
14 Hours, 6 Minutes, 23 Seconds. Excuse me?
Unless certain companies have now started incorporating space-time
continuum shifting algorithms into their backup software, there was
something seriously wrong. I mean, I'm not even sure how this would even
work - although I have a few working theories.
- My software is trying to impress me.
"Oh man I was so pooped Mr Network Manager, I squeezed 126 Days
work into just 72 hours. Am I good or what? Go on, gimme that RAM
upgrade you keep giving the Penguins."
Verdict - I know this OS well. Not possible.
- We are backing up data close to light speed.
Owing to the well know time dilation effect, maybe it's possible
that the backup job was running in a different frame of reference
to the rest of the machine.
Verdict - Not feasible.
- We travel back in time and archive the data before it's even
been created.
"Yes that's right ladies and gentlemen, the new Backup 5000 will
archive your work before you've even done it."
Verdict - Begs the question, do I even need to bother doing the
work in the first place. Can't I just restore it from the backup
on the day it's due?
- There is a bug.
Someone has screwed up what should be a relatively simple task.
Something so simple, it was achieved, according to the Guinness
Book of Records, over 500 hundred years ago: A working clock.
I learnt to tell the time at a fairly early age. Not as early as some of
those super boff infants, who can point to the big and little hand at the
age of 3, but simple time concepts, for example elapsed time, weren't
exactly rocket science. It begs the question: if some programmers can't
even tell the time, can we really entrust them with the safety and security
of our collection of nuclear missiles? It does, however, explain the Y2K
problem quite nicely. I can see the conversation now:
Person A: "So what do you do for a living?"
Person B: "I'm a programmer, I make computers do things."
Person A: "So you must be good at maths then?"
Person B: "If there's a sum I can't do, I haven't met it yet."
Person A: "What's 1999 + 1?"
Person B: "There are numbers after 1999? Bugger!"
By contrast, my Linux server seems to be able to tell the time quite well.
Perhaps it's the collaboration of hundreds of Open Source programmers, who
all, like me, were taught that elapsed time needn't be a complicated
concept involving time machines. In fact, my backup routine doesn't even
inform me of the time taken to perform the process. It doesn't need to. I
don't have to acknowledge that it's done its nightly job every morning
with the click of an OK button. I stick the tape in, punch a few keys,
whisper the words "Go Crazy", and off she goes. That's probably the main
difference between the two. I trust my linux server to do its job. I
trust the others to need assistance.
Wednesday came and I began to lose all faith and sanity. This one's a
tricky one to explain... suffice it to say we have a database storing
information and a framework to access it. This was all purchased from a
company, along with client access licenses (another great money making idea
for the corporate fat cats) at some huge cost. My bosses decided to
purchase another module for this framework. What happened next made me
angry beyond belief:
- The supplier wanted to charge £7,000 for this module
- "To be on the safe side" we were advised to purchase separate CAL's for
each workstation.
I began to Moo [1]. Talk about milking it. Was it just me or did no one else
see the gleaming pound/dollar/yen/other (delete whichever is appropriate)
sign in the suppliers eyes?
The homo-sapien pauses for a breath and some malt-loafy goodness.
I'm not completely naive. I know some things must be charged for - Open
Source food, anyone? I just feel that £7,000 and a further £1,500 a year
for support for a module, that's right, folks - a module! - is about as sensible
as drinking a vat of hydrochloric acid. One leaves a hole in your pocket,
the other leaves a hole in your stomach. Go figure. Take into account
also that this is an educational establishment, and you have a recipe for
what I would consider severe injustice. Perhaps some of these companies
are starting to claim back their future programmers wages already. Couple
that with the fact that a developers license costs a mere £20,000 and my
brain was just about ready to spread its wings and leave.
I mused for a while about whether there was an Open Source alternative.
Google confirmed my suspicions. The problem being, from my experience,
people just don't trust open source. According to one particularly
uninformed individual I once met, it's evil. I begged to differ, but
shortly afterward wished I hadn't. People seem to be scared of Open
Source. The fact that the code has been checked by hundreds, if not
thousands of programmers, and is available for all to see, is apparently a
bad thing. I fail to see why. True, it's not without its problems, but the
availability of free, customisable code wins over extortionate, closed
source binaries any day. My advice: if you haven't already, try it.
24 hours later and I had decided not to keep track of time again until the
weekend. I sat down to debug a particularly nasty CPU hog present on a
user's laptop. After trying to ascertain the problem for what seemed like a
few millennia, a strange thing happened. I was on my knees. That's right,
I was actually begging my machine to show me what was happening. I'd given
it the three-fingered salute, and it had thrown back something equally
abusive, but I found myself pleading with it to give me some indication of
what it was actually doing. The normal RAM bribes did nothing, and I was
fresh out of ideas.
I can understand that for a desktop system, usability and nice, pretty,
fluffy GUI's are almost mandatory, but there should, somewhere at least, be
a method of viewing what's actually going on inside. My mind cut to a day
dream. I imagined two monkeys. The first was sitting in front of a
monitor with his glasses on, intently reading white text on a black screen
whizzing by. He occasionally tapped a key or two and made satisfied "oooh
ooh" noises at what he saw. Did I mention he was wearing a Debian
tee-shirt and was called Henry? The second monkey sat on top of his
monitor. The screen was showing a signal test, the case was off the side
of the computer and monkey number two - I decided to call him Monty - was
yanking various cards, chips and drives out of his machine, inspecting each
one and giving it a gentle lick before throwing them at Henry. Cut to the
end of the daydream, just before the credits:
Monty never did solve his problem and was committed to an asylum for
the technically insane.
Henry recompiled his kernel that afternoon and went on to run a
successful clinic, caring for the technically insane.
At this point in time, I felt a lot like Monty. Tired, lonely, and insane.
Would licking my machine help? I quickly shunned the idea and went to
lunch, in search of tastier things.
Had I been working at my linux box, I could have gathered all the
information I wanted. A quick "top" command and I would have been
presented with a list of all processes running on the system, their
priorities, CPU Usage, Memory Usage, execution time, and maybe even been asked
the question, "Do you want fries with that?" The main point to take away
from this experience is that Linux is helpful. I can go as shallow or as
deep into a problem as I like. From "It's broken", the kind of response a
user normally gives, to performing an "strace -p " command and
actually viewing the execution calls as and when they are happening.
Granted it may seem more complicated at first, but why be like Monty when
you can be like Henry?
Friday. The last day of the week. Excuse me for stating the obvious but
at this stage even the facts seemed to be going astray. Surely, today would
be kinder to me.
It didn't start well. Whilst munching on my breakfast, I
decided to try to pay my gas bill. Having had little trouble paying it
on-line before, I sat down and loaded faithful Firefox. After remembering
my stupidly long and arduous authentication credentials [2], I was presented
with my balance. I clicked on "Pay" and a feeling of darkness swept over
me. I had a premonition that something was about to go horribly wrong; a
common feeling in IT. The page cleared itself as it usually does and I
waited and waited and waited. I looked under the desk to see if the little
gremlins inside the router were flashing their torches at me, they were. I
squinted back at the screen searching for the little spinning "loading"
logo in the top right corner [3]. To my shock and horror it wasn't
spinning. I refreshed the page; Same result. The page had apparently
finished loading. How useful, a blank form with which to pay my bill. Do
I sound sarcastic? I emailed the company to complain about a distinct lack
of functionality, which I must admit I found difficult to describe.
Please describe the nature of the problem: "Nothing (Nuh-fing): A blank
screen where a payment form should be."
Upon arriving home I loaded my inbox. I'm not quite sure what I was
expecting, but something useful surely.
Dear Sir blah blah
I'm sorry but we currently only support Browser A.
I suggest you use this to pay your bills in future.
We are thinking of introducing cross compatibility but not at this stage.
-- Company X
Well shut my mouth. No, seriously, before the abuse just falls out. 100
Million people use the same browser I do! I guess that puts us in the
minority, fellow fire-foxians! Excuse the sarcasm. I was immediately aware
that the wall, which had previously been vertical and inanimate had started
to hurl itself over my head. It took a few seconds to register that it was
in fact ME banging MY head against the proverbial wall. This must be some
kind of new stupidity warning device. The whole cross-compatibility
support issue really bugs me. Why does the rest of the world insist on
their own proprietary formats, when Open Source developers have been
sharing theirs for years? Many Open Source packages will even read
proprietary formats and often write to them too. OpenOffice is a great
example. Not only can I work with the .odt format; a nice small file type,
but I can also load the more common .doc format, and write to it. Did I
mention I can sing a little ditty while I do all this too?
Several paracetamol later, I went up to bed and slept. Oh, did I sleep. I'd
earned it. In short, I guess by writing this article I'm hoping some
curios non-Linuxian/non-Open Sourcian will read it and think... there's
another way? Yes, that's right, kiddies - you don't have be like Monty the
monkey, you can solve problems the easy way. The brick wall needn't be
your friend. You don't need a large bank balance to make it in life. You
can have your cake and eat it. Linux is #1. Oh sheesh, who am I kidding,
one monkey can't change the world!
[1] Mooing in an office environment is not generally advised, you tend to get
strange looks followed by strange nicknames like Buttercup and Daisy.
However, when the person calling you these nicknames is built like a
Challenger II tank, you just simply smile and accept your shiny new office
nickname. Keeps them from breaking their computers, I guess. Bless.
[2] It always fascinates me the information that companies choose to use for
jogging our memory.
Pet's name - Because obviously pets are immortal and never die.
Favorite Colour - Another no-brainer, ask 100 people what 'turquoise' is. A
large sea mammal? Generally users will either pick, Red, Green, Yellow,
Blue, Black or White. If you get a really intelligent end user, we might
get something as adventurous as purple, or sky blue. Heck - while we're at
it, why not just go crazy? Here are a list of my
favorites:
Favorite brand of hair conditioner.
Favorite insult.
Weight of my spouse in grams.
Cups of coffee consumed from birth till 21/09/2003
Enough!!
[3] It's when you've had a week like this that your brain starts to
devolve. Complicated computing terms such as "browser processing
indicator" are replaced by "little spinning loading logo", "food" becomes
your "life force" and your "computer" becomes your "time-wasting device."
Pete has been programming since the age of 10 on an old Atari 800 XE.
Though he took an Acoustical Engineering degree from the world-renowned
ISVR in Southampton UK, the call of programming brought him back and he
has been working as a Web developer ever since. He uses both Linux and
Windows platforms. He still lives in the UK, and is currently living
happily with his wife.
Copyright © 2005, Pete Savage. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005
Ecol
By Javier Malonda
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that
supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The
strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
To see a panel in all its clarity, click on it.
All Ecol cartoons are at
tira.escomposlinux.org (Spanish),
comic.escomposlinux.org (English)
and
http://tira.puntbarra.com/ (Catalan).
The Catalan version is translated by the people who run the site; only a few
episodes are currently available.
These cartoons are copyright Javier Malonda. They may be copied,
linked or distributed by any means. However, you may not distribute
modifications. If you link to a cartoon, please notify Javier, who would appreciate
hearing from you.
Copyright © 2005, Javier Malonda. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 121 of Linux Gazette, December 2005

![[cartoon]](misc/ecol/ecol-194-e.png)
![[cartoon]](misc/ecol/ecol-199-e.png)